统一计算架构(Compute Unified Device Architect-ure,CUDA)是英伟达(NVIDIA)公司近年来推出的通用并行计算架构,它以高性能显卡GPU为硬件依托,采用CPU+GPU的混合计算极大的提高了大规模的图形数据实时处理效率。本文设计的视频显示系统,采用CUDA开发方式实现了计算机桌面图片的分割计算、贝塞尔曲线拟合、以及融合图像计算等三方面处理。实时性高,画面数据计算理论上精确值14像素,精度好。
1 系统框架设计
图像处理的本质是大规模矩阵运算,特别适合并行处理。但CPU通用计算很难利用该特性。与此相反,GPU在并行数据运算上具有强大的计算能力,特别适合作运算符相同而运算数据不同的运算,当执行具有高运算密度的多数据元素时,内存访问的延迟可以被忽略。CUDA编程模型将CPU作为主机(Host),GPU作为协处理器(Coprocessor)或设备(Device),一个系统中可以存在多个设备。在这个模型中,CPU与GPU共同工作,CPU负责逻辑性强的事务处理和串行计算,GPU则专注于执行高度线程化的并行处理任务。
本系统以NVIDIA GeForce GTX470搭建的计算平台为运行环境,利用显卡的多头输出特性,连接多台投影仪组成拼接屏幕阵列,不需要额外增加其他硬件设备。由于桌面融合显示系统要处理的图像数据大、实时性高的特点,所以本系统的软件设计上则广泛使用了多CPU并行编程技术和CUDA并行计算技术,针对每一个投影设备的图像处理和显示,系统会分配一个专门的线程来处理。该线程会对应固定的CPU和固定的GPU计算核心,保证多投影设备完全并行处理,从而避免了其他系统由于显示设备增多,处理数据变大而造成的性能下降。CUDA架构如图1所示。
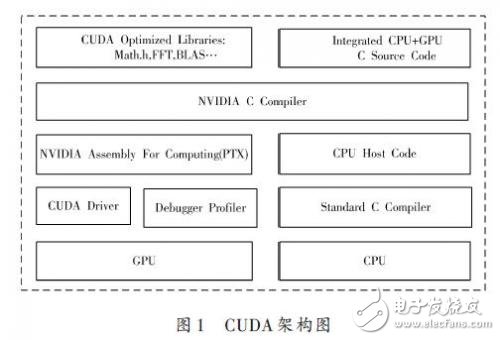
本系统在设计中,首先设置定时器。定期采集控制屏幕图像信息保存到公共存储空间,然后针对外设显示设备个数动态的开启数个线程完成图像的数据分割、图像的数据融合以及图像的显示等工作。其中在线程开启初始就与固定的GPU计算核心相关联,并把数据图形分割和融合部分采用CUDA技术进行实现,最后同样采用定时器技术同步各个线程中图像数据显示工作。
通常采用贝塞尔曲线拟合方法来完成图像数据的融合。该方法的一般做法是先由控制点得出目标图像每行的贝塞尔曲线,组成二维贝塞尔曲面,再将目标图像数据采用贴纹理的方法拟合到贝塞尔曲线上从而实现图像变形。Bezier曲线是一种用控制多边形定义曲线和曲面的方法。它的拟合插值公式为:

式中:Pi为构成该曲线的特征多边形;Bi,n(t)是Bezier基函数,是曲线上各点位置矢量的调和函数。Bezier曲线的始点、末点与其特征多边形端点重合,且始点、末点的切线方向与特征多边形的第一和最后一条边一致。
该曲线具有凸包性、对称性等特性。贝塞尔曲线的优点是给定足够的控制点后,它能够拟合任意形状的曲线。
Bezier曲线的拟合插值公式中,函数的次数是与特征多边形的顶点数相应的,当特征多边形顶点数为4时,就构成三次Bezier曲线。三次Bezier曲线的拟合插值公式为:

OPenGL技术提供了易于操作的贝塞尔曲线生成函数和贴图函数,但却无法控制硬件运算,效率不高。本系统出于对时效性的考虑在实现过程中并未采用该方法,而是采用CUDA技术并行矩阵运算的方式来进行纹理贴图。根据CUDA程序的结构特点,本系统处理时,首先根据人机交互部分得到的控制点信息采用通常方法生成目标图像每行的贝塞尔曲线。开辟显存存入GPU,然后对应CUDA程序结构,针对目标图像上的每一个像素点,为其分配一个GPU thread来进行处理。
观察上面的计算公式发现,当获得了初始控制点坐标后,在得出每一条贝赛尔曲线上的点的过程中,彼此并不影响,具有多线程的粗粒度的特性,所以CUDA并行计算的时效性有很大的提高。
2 性能评估
在多媒体拼接系统中实时性是最基本、也是最重要的指标。我们观看到的大屏幕拼接动态效果是由一帧一帧图片快速显示而产生的。根据正常的人眼视觉残留水平系统要达到显示流畅的画面,1s要处理至少25张图片,也就是说整个程序一次图像处理流程不会超过40ms.下面本文将分析一下该系统的时效性。
由于图像采集部分和处理部分采用的是异步方式,时间复用,而显然处理部分的耗时又远远超过采集部分,所以只列出处理部分的时间消耗,又因为该部分效率主要受显卡GPU性能影响,所以之对比不同型号GPU的时间消耗情况。具体如表1所示。
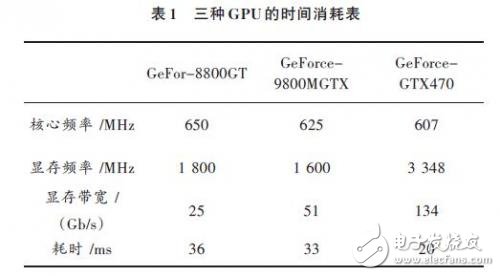
由此我们看出采用GeForce8800GT显卡可以基本上完成显示功能,而采用GeForce GTX470则可以每秒钟显示35~40张图片,是用户完全感觉流畅的视频体验。
3 结语
今年来大屏幕对计算机操作演示的需求越来越多,而高性能显卡的发展又促使GPU计算逐渐成为大规模并行计算重要的解决途径。本系统采用了CUDA技术实现了视频拼接系统,目前本系统采用两个双头显卡组成显示功能模块最多实现四屏拼接,如果需要更多屏幕拼接显示时可以考虑使用网络C-S结构进行扩展。由于耗时的图像处理部分完全有GPU进行计算,屏幕越多需要计算的内容也随之增多,而同时系统显卡数量也会增多,所以该系统不会随着拼接屏幕增多而性能下降。由于系统总体采用并行技术,所以将来可以方便地为系统加入时下流行的人机互动模块、真实感渲染模块等部分,使之真正成为一款高性能多媒体展示系统,给用户一个全方位真实的体验。