继2015的YOLO后,2016年作者对YOLO升级到YOLO2,另外一个版本YOLO9000是基于wordtree跨数据集达到检测9000个分类,卷积层模型称为darknet-19,达到速度和效果的双提升,文章里充满了作者的自豪,也值得自豪;
作者正视了YOLO的两个大问题:回归框不精准和召回不够;一般的解决思路都是把网络加深加宽,不过本文不屑,作者反而要通过优化网络学习在准确率不降的情况下提升精度和召回!
升级点
Batch Normalization:每个卷积层加了BN,正则都不要了,droupout也省了,过拟合也没了,效果还好了,+2%mAP;
High Resolution Classifier - 高分辨率分类:模型训练时经典做法都是先在ImageNet上pre-train,然而ImageNet上的图片是低分辨率小于256*256的,而要检测的图片是高分辨率448*448的,这样模型需要同时在高分辨的图片上做fine-tune和检测,所以作者提出了三步骤 1) 在ImageNet低分辨率上pre-train;2) 在高分辨率数据集上fine-tune;3) 在高分辨率数据集上检测;使得模型更容易学习,+4%mAP
Convolution with Anchor Boxer - 加Anchor机制:YOLO是通过最后的全连接层直接预估绝对坐标,而FasterRCNN是通过卷积层预估相对坐标,作者认为这样更容易学习,因此YOLOv2去掉了全连接层,在最后一层卷积层下采样后用Anchor,yolo有7*7*2 = 98个框,而YOLOv2有超过1k的anchor,最终效果上虽然mAP略有下降3个千分点,但是召回提升7个百分点,值了!
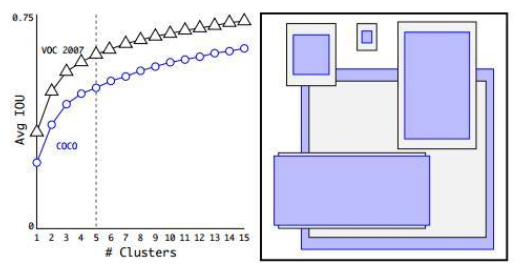
Dimension Clusters- 维度聚类: Anchor的尺寸faster rcnn里人工选定的,YOLOv2通过k-mean聚类的方法,将训练数据里gt的框进行聚类,注意这里不能直接用欧式距离,大框会比小框影响大,我们的目标是IOU,因此距离为: d(box, centroid) = 1 IOU(box, centroid);下图是结果,左图是k和IOU的trand-off,右图是5个中心的框尺寸,明显看出和人工指定的差异很大;
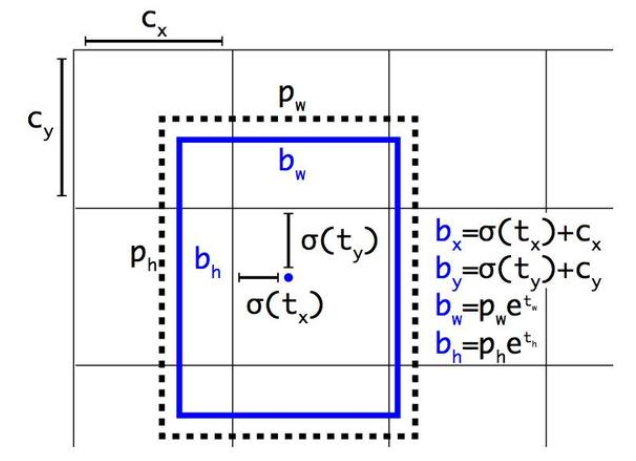
Direct location prediction - 直接预测位置:直接预测x,y会导致模型训练不稳定,本文预测如下tx,ty,tw,th,to,通过sigmolid归一化到(0,1),结合dimension clusters,+5%mAP
Fine-Grained Freture - 细粒度特征:引入passthrough layer,将低维度特征传递给高维度,类似于resnet的shortcut,+1%mAP;
Multi-Scale Training - 多尺度训练:这里的多尺度是图片的尺寸,多了迫使模型适应更大范围的尺寸,每隔一定的epoch就强制改变输入图片的尺寸;
效果
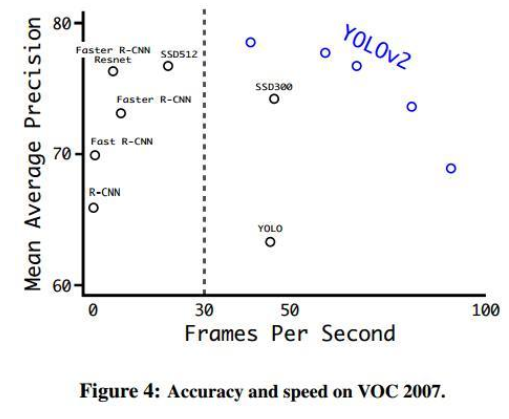
如下是在VOC数据集上效率(每秒处理帧数)和效果(mAP)空间里不同算法的变现,其中YOLOv2为蓝色,有不同的trade-off,效率和效果都超过已有的方法;
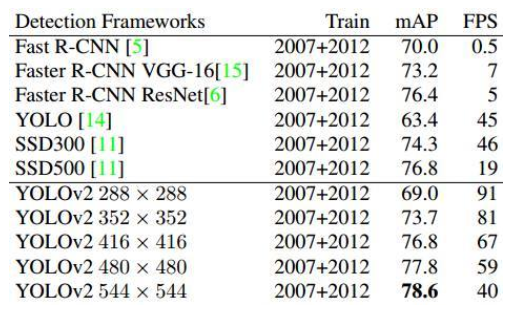
如下是更多的实验结果:
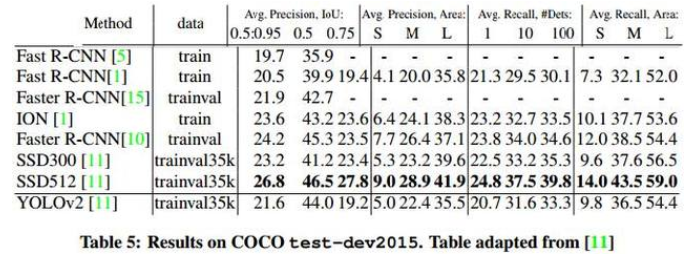
如下是COCO上的效果,看得出COCO数据集还是很难的,小物体上YOLO2依然是差一些;
YOLO9000: Better, Faster, Stronger